Saturday, July 30, 2005
IoC Containers Have Arrived
IoC containers have arrived big time and now are very much in mainstream software development - EJB3 has IoC features (no more JNDI lookup of resources and EJBs are required - these can be injected by container using Java 5 annotations - although JNDI lookup is supported). Time to read on IoC containers and in particular Spring. Geronimo guys are planning to use Spring for assembling Geronimo components - interesting. J2EE server uses Spring and Spring uses J2EE container services - that shows power of IoC and its applicability in developing flexible and loosely coupled systems.
Open Source Single Sign On Solutions
Some nice open source single sign-on solutions:
Not really a single-sign on solution but security solution designed for Spring:
Acegi Security project from Spring framework.
Not really a single-sign on solution but security solution designed for Spring:
Acegi Security project from Spring framework.
Tuesday, July 19, 2005
Double-Checked Locking is Broken in Java
The double-checked locking is broken in Java and it doesn't work. This declaration explains in great detail why?
Double-Checked Locking is Broken
This widely used idiom in singletons doesn't work:
An approach that will work is to do the following:
Double-Checked Locking is Broken
This widely used idiom in singletons doesn't work:
public class ClassA {
private static ClassA INSTANCE;
private ClassA() {
super();
init();
}
public static ClassA getInstance() {
if (null == INSTANCE)
synchronized (this) {
if (null == INSTANCE) {
INSTANCE = new ClassA();
}
}
return INSTANCE;
}
}
An approach that will work is to do the following:
public class ClassA {
private static final ClassA INSTANCE = new ClassA();
private ClassA() {
super();
init();
}
public static ClassA getInstance() {
return INSTANCE;
}
}
Sunday, July 17, 2005
Don't use java.rmi.server.UID for generating Unique IDs
There is a well known bug in java.rmi.server.UID in all the JDKs prior to Java 5. The problem occurs when two or more JVMs are running on the same host and are started exactly in the same millisecond. We found the bug the hard way while troubleshooting a real production problem that was rather painful.
UID as generated by java.rmi.server.UID is comprised of a host unique JVMID, followed by current time in milliseconds and followed by a sequence number as shown below:
JVMID – Time in milliseconds since Jan 1, 1970 – Seq No
An example UID is:
29b7fbc2 - 0000-0104-0bb5-afc9 - b2e0
where
29b7fbc2 - JVM Identifier unique to the machine.
0000-0104-0bb5-afc9 - Milliseconds since the epoch of 1970. In this example the value is May 23, 2005 18:39:13 EDT. This will change only when the sequence number rolls over. The JVM does not get the current time for every UID request in order to improve performance. Therefore, the msec time here is the time when the sequence number rolls over NOT the time when the UID was created.
b2e0 - Sequence number which counts from 8000 to 0 to 7FFF (in HEX).
UID is widely used as a starting point for generating unique Ids. We too used the UID: our UID scheme simply appended 3rd and 4th byte of host IP address to the number generated by java.rmi.server.UID. This UID was used as session identifier for web transactions with one of our legacy backend system. This scheme worked fine over a year and half without problem. Suddenly, about 2 months back, we started seeing duplicate sessions ids. Sometimes (we couldn’t nail how) one user would steal the transaction from another user and our backend system would actually commit the transaction incorrectly for the wrong user. We were puzzled and baffled. We looked at system clock for the UNIX server, thinking that the system clock was not ticking and time was not advancing (ruled out later, it started becoming random with respect to UNIX server). May be the time synchronization process for the cluster was setting the system clock back for these servers. After much analysis that was determined not be the case. We looked for similar problems but for the most part we were at a loss.
To give a brief idea of our system: it is a J2EE based very high volume web site. This system is consumer facing, 24 by 7, global e-commerce site and is a major revenue generating channel for the company. It interfaces with Mainframe based legacy systems for core business transactions. Another important aspect, to meet performance requirements, we had to stand up 2 JVMs per host about 8 months back.
Needless to say the heat was on, this problem although very miniscule (only 7 or 8 cases was reported among upwards of five hundred thousand transactions) nonetheless, it had everybody worried and more so since we were clueless. Company’s name and trust was at stake if this continued for long. The customers who’s transactions were messed up, called in our customer care line and got the problem resolved.
We got a lucky break a few weeks back when we were troubleshooting one such occurrence. It came to our attention that this problem started after a cluster switch was performed and ripple start of 2nd set of JVMs was executed. Then somebody mentioned that last time also the problem started after a server restart. That got us thinking – something to do with JVM restarts – at least some semblance of repeatable pattern. We had always fixed the problem by shutting down the offending application servers and re-starting them. What if there is a bug in UID generation? We knew for sure that the last 2 bytes of the UID will be same for all UIDs on a given host. How is JVM id determined? Does it use start up time (we had actually ruled this out earlier assuming Java will have a smarter way of guaranteeing JVM uniqueness on a host and must not be based on JVM startup time. Bad assumption)? We googled “bug in java.rmi.server.UID” and there it was !! (we love google, the best customer support and knowledge base in the world). We quickly copied the programs posted with the bug in the Sun’s Java bug database to reproduce the problem and sure enough we did it very reliably. So under some circumstances our ripple start scripts were starting the two application servers (or JVMs) on a given host in the cluster exactly at the same millisecond and when it happened (which was very random to us since we have 11 servers with 26 JVMs in our primary cluster) the two JVMs would start generating duplicate UIDs.
Moral of the story, don’t rule out bugs in core Java libraries and don’t assume that Sun is always very smart and will always have elegant solutions. And please use google or search Sun's Java bug database for finding Java bugs first. It might just save many a heart burns and sleepless nights. We were dumbfounded to learn that this bug has been in Java since its inception and the bug was first filed in 1999. Second all of us were looking rather chastised and humbled, how come we didn’t know? Most of us have been working with Java since 1998.
Note: Please see the bug description for details of the bug and the circumstances under which it can occur. Our fix was that we wrote our own UID generator. Java 5 fixes the problem by using new SecureRandom().nextInt() (see source code in src.zip in $JAVA_HOME distributed with JDK 5, src/java/rmi/server/UID.java) for JVM unique id instead of new Object().hashCode() (see source code in src.zip in $JAVA_HOME distributed with JDK 1.4, 1.3, 1.2 etc., src/java/rmi/server/UID.java) in pre Java 5 versions.
UID as generated by java.rmi.server.UID is comprised of a host unique JVMID, followed by current time in milliseconds and followed by a sequence number as shown below:
JVMID – Time in milliseconds since Jan 1, 1970 – Seq No
An example UID is:
29b7fbc2 - 0000-0104-0bb5-afc9 - b2e0
where
29b7fbc2 - JVM Identifier unique to the machine.
0000-0104-0bb5-afc9 - Milliseconds since the epoch of 1970. In this example the value is May 23, 2005 18:39:13 EDT. This will change only when the sequence number rolls over. The JVM does not get the current time for every UID request in order to improve performance. Therefore, the msec time here is the time when the sequence number rolls over NOT the time when the UID was created.
b2e0 - Sequence number which counts from 8000 to 0 to 7FFF (in HEX).
UID is widely used as a starting point for generating unique Ids. We too used the UID: our UID scheme simply appended 3rd and 4th byte of host IP address to the number generated by java.rmi.server.UID. This UID was used as session identifier for web transactions with one of our legacy backend system. This scheme worked fine over a year and half without problem. Suddenly, about 2 months back, we started seeing duplicate sessions ids. Sometimes (we couldn’t nail how) one user would steal the transaction from another user and our backend system would actually commit the transaction incorrectly for the wrong user. We were puzzled and baffled. We looked at system clock for the UNIX server, thinking that the system clock was not ticking and time was not advancing (ruled out later, it started becoming random with respect to UNIX server). May be the time synchronization process for the cluster was setting the system clock back for these servers. After much analysis that was determined not be the case. We looked for similar problems but for the most part we were at a loss.
To give a brief idea of our system: it is a J2EE based very high volume web site. This system is consumer facing, 24 by 7, global e-commerce site and is a major revenue generating channel for the company. It interfaces with Mainframe based legacy systems for core business transactions. Another important aspect, to meet performance requirements, we had to stand up 2 JVMs per host about 8 months back.
Needless to say the heat was on, this problem although very miniscule (only 7 or 8 cases was reported among upwards of five hundred thousand transactions) nonetheless, it had everybody worried and more so since we were clueless. Company’s name and trust was at stake if this continued for long. The customers who’s transactions were messed up, called in our customer care line and got the problem resolved.
We got a lucky break a few weeks back when we were troubleshooting one such occurrence. It came to our attention that this problem started after a cluster switch was performed and ripple start of 2nd set of JVMs was executed. Then somebody mentioned that last time also the problem started after a server restart. That got us thinking – something to do with JVM restarts – at least some semblance of repeatable pattern. We had always fixed the problem by shutting down the offending application servers and re-starting them. What if there is a bug in UID generation? We knew for sure that the last 2 bytes of the UID will be same for all UIDs on a given host. How is JVM id determined? Does it use start up time (we had actually ruled this out earlier assuming Java will have a smarter way of guaranteeing JVM uniqueness on a host and must not be based on JVM startup time. Bad assumption)? We googled “bug in java.rmi.server.UID” and there it was !! (we love google, the best customer support and knowledge base in the world). We quickly copied the programs posted with the bug in the Sun’s Java bug database to reproduce the problem and sure enough we did it very reliably. So under some circumstances our ripple start scripts were starting the two application servers (or JVMs) on a given host in the cluster exactly at the same millisecond and when it happened (which was very random to us since we have 11 servers with 26 JVMs in our primary cluster) the two JVMs would start generating duplicate UIDs.
Moral of the story, don’t rule out bugs in core Java libraries and don’t assume that Sun is always very smart and will always have elegant solutions. And please use google or search Sun's Java bug database for finding Java bugs first. It might just save many a heart burns and sleepless nights. We were dumbfounded to learn that this bug has been in Java since its inception and the bug was first filed in 1999. Second all of us were looking rather chastised and humbled, how come we didn’t know? Most of us have been working with Java since 1998.
Note: Please see the bug description for details of the bug and the circumstances under which it can occur. Our fix was that we wrote our own UID generator. Java 5 fixes the problem by using new SecureRandom().nextInt() (see source code in src.zip in $JAVA_HOME distributed with JDK 5, src/java/rmi/server/UID.java) for JVM unique id instead of new Object().hashCode() (see source code in src.zip in $JAVA_HOME distributed with JDK 1.4, 1.3, 1.2 etc., src/java/rmi/server/UID.java) in pre Java 5 versions.
Saturday, July 16, 2005
Commons Logging - To Use or Not To Use
Now that we have looked at Java ClassLoading in detail, its time to take a look at Apache Jakarta Commons Logging and answer the question: whether to use or not to use Commons Logging in J2EE environment? Commons Logging provides a nice abstract logging API, insulating application code from being tied to a specific logging implementation. Use of Commons Logging provides portability across logging implementations such as log4j or jdk logging. On the face of it this looks like a neat idea. I can change the logging implementation without changing a line of code. However that was not the intent of Commons Logging (See Rod Waldoff’s blog) and there are well known problems using Commons Logging in J2EE environment due to ClassLoader problems and auto-discovery of a logging implementation and logging configuration. Ceku Gulcu, creator of log4j, has a detailed technical discussion on classloader problem. Ceku Gulcu takes a detailed look at problems using Commons Logging in this article “Think again before adopting the commons-logging API”. From this article:
A downside of using Commons Logging is that it takes away some of the advance features of an underlying logging implementation (being an abstraction across various logging implementation, it can only support features common across logging frameworks) such as Nested Diagnostic Context (NDC) or Mapped Diagnostic Context (MDC) capability of log4j. Another issue with it is that it makes logging component a tad complex. And it can introduce problems which can be difficult to debug. One can waste hours debugging classloader issues or why your application is not reading your logging configuration. All this complexity is unwarranted. Even creator of Commons Logging Rod Waldhoff has acknowledged “Commons Logging was my fault”.
Inspite of these problems Commons Logging has its utility. So when and where should it be used? Again from Rod Waldhoff’s blog:
“The commons-logging API supporting multiple logging frameworks has its own "discovery process" which is based on the resources available to a particular classloader. In addition, the commons-logging API will create its own logger wrapper for each and every class loader in use within your application. The class loader based automatic "discovery process" is the principal weakness of the commons-logging API because it results in a substantial jump in complexity.”
A downside of using Commons Logging is that it takes away some of the advance features of an underlying logging implementation (being an abstraction across various logging implementation, it can only support features common across logging frameworks) such as Nested Diagnostic Context (NDC) or Mapped Diagnostic Context (MDC) capability of log4j. Another issue with it is that it makes logging component a tad complex. And it can introduce problems which can be difficult to debug. One can waste hours debugging classloader issues or why your application is not reading your logging configuration. All this complexity is unwarranted. Even creator of Commons Logging Rod Waldhoff has acknowledged “Commons Logging was my fault”.
Inspite of these problems Commons Logging has its utility. So when and where should it be used? Again from Rod Waldhoff’s blog:
“In fact, there are very limited circumstances in which Commons Logging is useful. If you're building a stand-alone application, don't use commons-logging. If you're building an application server, don't use commons-logging. If you're building a moderately large framework, don't use commons-logging. If however, like the Jakarta Commons project, you're building a tiny little component that you intend for other developers to embed in their applications and frameworks, and you believe that logging information might be useful to those clients, and you can't be sure what logging framework they're going to want to use, then commons-logging might be useful to you.”
Saturday, July 09, 2005
WebSphere 5.x Classloaders.
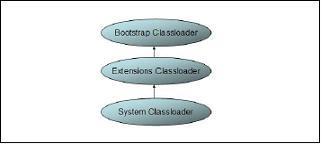 Picture 1 Java Classloader Hierarchy.
Picture 1 Java Classloader Hierarchy.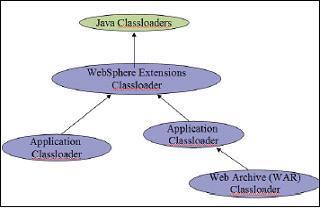 Picture 2 WebSphere Classloader Hierarchy.
Picture 2 WebSphere Classloader Hierarchy.Java Classloaders
The standard Java (JSE) VM has three classloaders: the bootstrap classloader, the extensions classloader, and the system classloader.
Bootstrap Classloader: The bootstrap classloader is responsible for loading the core Java libraries, that is
Extensions classloader: The extensions classloader is responsible for loading the code in the extensions directories (
System Classloader: The system classloader is responsible for loading the code that is found on java.class.path, which ultimately maps to the system CLASSPATH variable. This classloader is implemented by the sun.misc.Launcher$AppClassLoader class.
Picture 1 shows the standard Java classloader hierarchy.
Delegation is a key concept to understand when dealing with classloaders. It states which classloader in the classloader hierarchy loads a class. By default when a Java program needs a class, the context (or current) classloader delegates class loading to its parent before trying to load the class itself. This is the default policy for standard JVM classloaders. For example if the system classloader needs to load a class, it first delegates to the extensions classloader, which in turn delegates to the bootstrap classloader. If the parent classloader cannot load the class, the child classloader tries to find the class in its own repository. In this manner, a classloader is only responsible for loading classes that its ancestors cannot load. A classloader can only find classes up in the hierarchy, not down. This is a very important concept because at runtime if a class tries to load a class not visible to the classloader that loaded it or any of it parents then NoClassDefFoundError will be thrown.
WebSphere Application Server 5.x classloader hierarchy is shown in picture 2 above.
In general each enterprise application (EAR) gets its own classloader and each web application (WAR) within an EAR or without an EAR i.e. standalone WAR gets its own classloader. All EJB JAR files within an application are always loaded by the same classloader. The application classloader policy and WAR classloader policy control the actual runtime classloader hierarchy.
WebSphere Extensions Classloader
The WebSphere extensions classloader, whose parent is the Java system classloader, is primarily responsible for the loading of the WebSphere class libraries in the following directories:
-
-
-
-
The WebSphere runtime is loaded by the WebSphere extensions classloader based on the ws.ext.dirs system property, which is initially derived from the WS_EXT_DIRS environment variable set in the setupCmdLine script file found in $WAS_HOME/bin directory. The default value of ws.ext.dirs is the following:
SET WAS_EXT_DIRS=%JAVA_HOME%/lib;%WAS_HOME%/classes;%WAS_HOME%/lib;
%WAS_HOME%/lib/ext;%WAS_HOME%/web/help;
%ITP_LOC%/plugins/com.ibm.etools.ejbdeploy/runtime
The RCP directory is intended to be used for fixes and other APARs (IBM terminology for patches) that are applied to the application server runtime. These patches override any copies of the same files lower in the RP and RE directories. The RP directory contains the core application server runtime files. The bootstrap classloader first finds classes in the RCP directory then in the RP directory. The RE directory is used for extensions to the core application server runtime. Each directory listed in the ws.ext.dirs environment variable is added to the WebSphere extensions classloaders classpath. In addition, every JAR file and/or ZIP file in the directory is added to the classpath. You can extend the list of directories/files loaded by the WebSphere extensions classloaders by setting a ws.ext.dirs custom property to the Java virtual machine settings of an application server.
Application Extensions Classloader
In WebSphere Application Server Version 4.0, one could drop JAR files under
Shared Libraries
It is recommended that shared libraries be used to point to a set of JARs (for example, a framework), and associate those JARs to an application or application server.
Shared libraries consist of a symbolic name, a Java classpath, and a native path (for loading JNI libraries), and can be defined at the cell, node, or server level. However, defining a library at one of the three levels does not cause the library to be loaded. The library must associated to an application and/or application server in order for the classes represented by the shared library to be loaded.
If shared library is associated to an application (EAR), the JARs listed on the shared library path are loaded by the application classloader (together with EJB JARs, RARs and dependency JARs). If the the shared library is associated at the application server level, the JARs listed on the shared library path are loaded by a specific classloader (which you have to define).
Classloading and Delegation mode
There are two possible values for a classloader loading mode: PARENT_FIRST and PARENT_LAST. The default value for classloading mode is PARENT_FIRST. This policy causes the classloader to first delegate the loading of classes to its parent classloader before attempting to load the class from its local classpath. This is the default policy for standard JVM classloaders. If the classloading policy is set to PARENT_LAST, the classloader attempts to load classes from its local classpath before delegating the classloading to its parent. This policy allows an application classloader to override and provide its own version of a class that exists in the parent classloader. Delegation mode can be set for the following classloaders: application classloader, WAR classloader, and shared library classloader.
Classloader Policies
For each application server in the system, the application classloader policy can be set to Single or Multiple.
Single: When the application classloading policy is set to Single, a single application classloader is used to load all EJBs, dependency JARs, and shared libraries within the application server (JVM). If the WAR classloader loading policy has been set to Application, the Web module contents for this particular application are also loaded by this single classloader.
Multiple: When the application classloading policy is set to Multiple, each application will receive its own classloader for loading EJBs, dependency JARs, and shared libraries. Depending on whether the WAR classloader loading policy is set to Module or Application, the Web module may or may not receive its own classloader.
For web application, the WAR classloader policy can be set to Module or Application.
Module: When the WAR classloading policy is set to Module, the Web module gets its own WAR classloader and it loads classes for the Web module.
Application: When the WAR classloading policy is set to Application, the Web module does not get its own WAR classloader. The Web module classes are loaded by application classloader (either single or multiple guided by application classloading policy).
Reloadable Classloaders
The application (EAR classloader) and the Web module classloaders (WAR classloader) are reloadable classloaders. They monitor changes in the application code to automatically reload modified classes. This behavior can be altered at deployment time.
![]()