Saturday, September 22, 2007
JMS - Message Prefetch Size
Many JMS providers implement message prefetch size (see Active MQ's what is the prefetch size?). A receive() call on message consumer reads number of messages as set by prefetch size. For the most part this is a good thing since message delivery is batched such that consumer always has messages to process. However this can also hurt performance if there are multiple receivers i.e. multiple message consumers are running on same hardware (vertical scaling) or on different hardware(s). We ran into this problem with Glassfish JMS provider. We had multiple legacy integration gateways running in a combination of vertical/horizontal scaled deployment but we did not see an increase in message processing throughput by legacy gateways. As matter of fact out of six gateways 4 of them were idle for the most part, doing nothing. The reason these additional gateways were idle as it turns out was due to Glassfish JMS's default message prefetch size of 1000 (Open MQ, Glassfish's JMS implementation, calls this imqConsumerFlowLimit). In our tests we had under 2000 messages, so the first two consumer to issue read would 1000 each. Thus other 4 gateways had nothing to read off the queue and hence nothing to do. We brought it down to 1 and all gateways started to process messages and overall system throughput increased significantly. In our case gateways are I/O bound calling into legacy application and waiting for results. So for our application prefetch size of 1 was optimal. In other applications, a different prefetch size is going to be optimal. The lesson, as always with performance optimization is: profile your application, find hot spots or performance bottlenecks of the application and then optimize. There is no one size fits all with regards to performance.
Wednesday, September 19, 2007
Planning Fallacies
Interesting articles on challenges in project/activity planning.
Planning Fallacy
Kahneman's Planning Anecdote
Planning Fallacy
Kahneman's Planning Anecdote
Tuesday, September 11, 2007
An Empirical Comparison of Seven Programming Languages
An Empirical Comparison of Seven Programming Languages
Interesting study on effectiveness of various programming languages, also some insight into how a programming language influences programmers' thinking and approach to a problem.
Here is a ruby solution. More information on this puzzle.
Seemingly a simple problem, but solution is far from trivial, more so if performance and memory efficiency is taken into consideration.
Interesting study on effectiveness of various programming languages, also some insight into how a programming language influences programmers' thinking and approach to a problem.
Here is a ruby solution. More information on this puzzle.
Seemingly a simple problem, but solution is far from trivial, more so if performance and memory efficiency is taken into consideration.
Sunday, July 01, 2007
Class in Interface
One can have a class in an interface using nested classes (i.e. static inner classes).
The inner class in an interface is nested class - it is public and static.
public interface ClassInInterface {
void helloWorld();
class Test implements ClassInInterface {
public void helloWorld() {
System.out.println("Hello World!");
}
public static void main(String[] args) {
new Test().helloWorld();
}
}
The inner class in an interface is nested class - it is public and static.
Saturday, June 30, 2007
Leaking Exceptions in Java
The try/finally block in Java can leak exceptions due to programming errors. The examples from Bruce Eckel's Thinking In Java (a gem of a book on Java) demonstrates how this part is broken in Java if programmer is not careful:
yet another example of how exceptions can be lost:
public class ExceptionSilencer {
public static void main(String[] args) {
try {
throw new RuntimeException();
} finally {
// Using 'return' inside the finally block
// will silence any thrown exception.
return;
}
}
}
yet another example of how exceptions can be lost:
class VeryImportantException extends Exception {
public String toString() {
return "A very important exception!";
}
}
class HoHumException extends Exception {
public String toString() {
return "A trivial exception";
}
}
public class LostMessage {
void f() throws VeryImportantException {
throw new VeryImportantException();
}
void dispose() throws HoHumException {
throw new HoHumException();
}
public static void main(String[] args) {
try {
LostMessage lm = new LostMessage();
try {
lm.f();
} finally {
lm.dispose();
}
} catch(Exception e) {
System.out.println(e);
}
}
}
Wednesday, November 01, 2006
SEDA Based Server Using Reactor Pattern
In one of my earlier blog entry on SEDA I mentioned that it would be interesting to marry SEDA and Reactor design pattern to implement a highly scalable, asynchronous event-driven driven network server. In this blog I describe design of a generic SEDA based server architecture and a Java implementation using Java NIO and Java Concurrent package.
A generic SEDA server architecture is shown in figure 2 below. Most server application design have following basic structure:

Figure 1
A SEDA stage consists of an incoming event queue queue, a thread pool and an application supplied event handler. What I have not shown here is stage controller that manages stage's operation and adjusts resource allocation and scheduling dynamically because these components are not implemented in the Java implementation of this architecture discussed later.
Geeting back to the server architecture, the stages in this architecture are:
Reactor - An asynchronous I/O event handler for network events occuring on sockets. Once an event is detected it is queued for Accepor stage to handle it. The Reactor provides asynchronous network I/O multiplexing.
Acceptor - This stage basically accepts client connection request, creates an IO session (more on this later) and queues the IO Session for Reader stage to take over.
Reader - This stage reads request from the socket stream and potentially after decoding, puts the request on the input queue of the next stage - the processor.
Processor - This stage is essentially calls application supplied event handler which process the client request.
Sender - This stage encodes and sends the response back to the client.

A generic SEDA server architecture is shown in figure 2 below. Most server application design have following basic structure:
- Listen for incoming requests
- Accept connection
- Read request
- Decode request
- Process request
- Encode response
- Send response
- Close the connection when client is done making requests

Figure 1
A SEDA stage consists of an incoming event queue queue, a thread pool and an application supplied event handler. What I have not shown here is stage controller that manages stage's operation and adjusts resource allocation and scheduling dynamically because these components are not implemented in the Java implementation of this architecture discussed later.
Geeting back to the server architecture, the stages in this architecture are:
Reactor - An asynchronous I/O event handler for network events occuring on sockets. Once an event is detected it is queued for Accepor stage to handle it. The Reactor provides asynchronous network I/O multiplexing.
Acceptor - This stage basically accepts client connection request, creates an IO session (more on this later) and queues the IO Session for Reader stage to take over.
Reader - This stage reads request from the socket stream and potentially after decoding, puts the request on the input queue of the next stage - the processor.
Processor - This stage is essentially calls application supplied event handler which process the client request.
Sender - This stage encodes and sends the response back to the client.
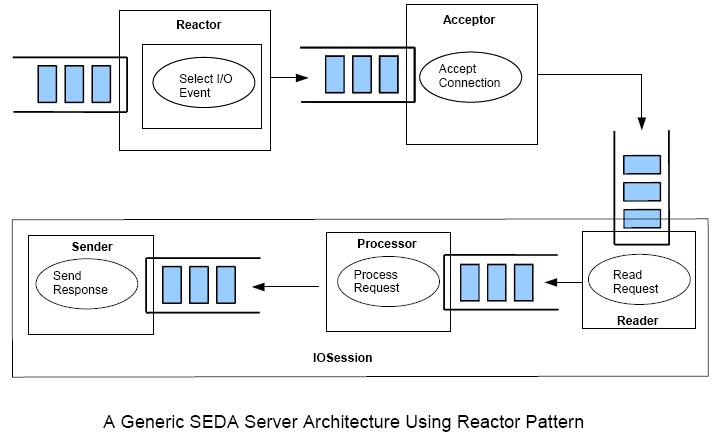
Figure 2
By separating I/O bound activities of the server - accepting connection, reading request and sending response in its own queue and thread pool, and keeping the core request processing in its own thread pool, the system can achieve very high scalability and performance. Under extreme load condition the admission control at each queue can throttle the request admission thus allowing the server provide reasonably good performance to existing clients and not accepting new client requests (this is one of the key aspect of SEDA architecture). If the Processor stage has required data cached in memory using various caching technologies, the Processor stage may be able to avoid I/O completly (such as database calls).
Figure 3 shows the Class diagram of a SEDA based server using Reactor pattern implemented in Java 5 using java NIO and concurrent package for thread pool management.
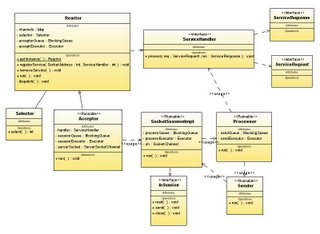
Figure 3 SEDA Server Implemented Using Reactor Design Pattern
Now the Java source code (for brevity only key aspects of each class are shown below:
Reactor
Acceptor
SocketSessionImpl
Processor
Sender
A service implementation using this framework has to implement the ServiceHandler interface which the Processor calls to invoke the service. An echo service could be implemented as:
Thread Pool Size
How many threads should the thread pools have? It depends on the kinds of tasks the worker threads perform. If the tasks in the work queue are compute-bound, then a thread pool of N or N+1 threads on an N-processor system will generally achieve maximum CPU utilization.
For tasks that may wait for I/O to complete i.e. they are mix of compute and I/O bound then application has to be profiled using profiling tools to get ratio of waiting time to service time for a typical service request. For an N-processor system a good thumb rule is to have N * (1 + waiting time/service time) threads in the pool for optimal performance and CPU utilization.
By separating I/O bound activities of the server - accepting connection, reading request and sending response in its own queue and thread pool, and keeping the core request processing in its own thread pool, the system can achieve very high scalability and performance. Under extreme load condition the admission control at each queue can throttle the request admission thus allowing the server provide reasonably good performance to existing clients and not accepting new client requests (this is one of the key aspect of SEDA architecture). If the Processor stage has required data cached in memory using various caching technologies, the Processor stage may be able to avoid I/O completly (such as database calls).
Figure 3 shows the Class diagram of a SEDA based server using Reactor pattern implemented in Java 5 using java NIO and concurrent package for thread pool management.

Figure 3 SEDA Server Implemented Using Reactor Design Pattern
Now the Java source code (for brevity only key aspects of each class are shown below:
Reactor
public class Reactor {
// Static variables and initializers
private final static Reactor INSTANCE = new Reactor();
final Logger logger = LoggerFactory.getLogger(Reactor.class);
// Instance Variables
private Selector selector;
private final Map channels = new HashMap();
private ArrayBlockingQueue acceptQueue =
new ArrayBlockingQueue(50);
private ThreadPoolExecutor acceptExecutor =
new ThreadPoolExecutor(5, 10,
2000, TimeUnit.SECONDS, sessionQueue);
public void registerService(SocketAddress address,
ServiceHandler handler) throws IOException {
ServerSocketChannel ssc = null;
ssc = ServerSocketChannel.open();
ssc.configureBlocking( false );
ssc.socket().setReuseAddress(true);
// and bind.
ssc.socket().bind(address);
ssc.register( selector,
SelectionKey.OP_ACCEPT, new Acceptor(handler, ssc) );
synchronized( channels )
{
channels.put( address, ssc );
}
}
public void run() {
for( ; ; )
{
try
{
int nKeys = selector.select();
if( nKeys > 0 )
{
processIOEvents( selector.selectedKeys() );
}
}
catch( IOException e )
{
logger.error("Main event loop thread exception:" + e );
....
}
}
}
private void processIOEvents( Set keys ) throws IOException
{
Iterator it = keys.iterator();
while( it.hasNext() )
{
SelectionKey key =
( SelectionKey ) it.next();
it.remove();
dispatch(key);
}
}
private void dispatch(SelectionKey key) {
Runnable r =
(Runnable) (key.attachment());
if (r != null)
acceptExecutor.execute(r);
}
}
Acceptor
public class Acceptor implements Runnable {
private ServiceHandler handler;
private ServerSocketChannel serverSocket;
private ArrayBlockingQueue sessionQueue = new ArrayBlockingQueue(50);
private ThreadPoolExecutor sessionExecutor = new ThreadPoolExecutor(5, 10, 2000,
TimeUnit.SECONDS, sessionQueue);
public Acceptor(ServiceHandler handler, ServerSocketChannel ssc) {
this.handler = handler;
serverSocket = ssc;
}
public void run() {
try {
SocketChannel ch = serverSocket.accept();
if( ch == null )
{
return;
}
SocketSessionImpl session =
new SocketSessionImpl(selector, ch, handler );
sessionExecutor.execute(session);
}
catch( Throwable t )
{
logger.error( "Error handling request for"+ t );
}
}
}
SocketSessionImpl
public class SocketSessionImpl implements IoSession, Runnable {
//-------------------------------------------------------------------------
// Static variables & static initializers.
//-------------------------------------------------------------------------
final Logger logger = LoggerFactory.getLogger(SocketSessionImpl.class);
//-------------------------------------------------------------------------
// Instance variables.
//-------------------------------------------------------------------------
public enum SESSIONSTATE {READING, SENDING}
public final int MAXIN=4096;
public final int MAXOUT=4096;
private final SocketChannel ch;
private final ServiceHandler handler;
private final SocketAddress remoteAddress;
private final SocketAddress localAddress;
private SelectionKey sk;
private ByteBuffer input = ByteBuffer.allocate(MAXIN);
private ByteBuffer output = ByteBuffer.allocate(MAXOUT);
private int readBufferSize;
private int bytesWritten;
private int writeTimeout;
private final Map attributes = new HashMap();
private final long creationTime;
private volatile SESSIONSTATE state = SESSIONSTATE.READING;
private static ArrayBlockingQueue ioQueue = new ArrayBlockingQueue(50);
private static ThreadPoolExecutor ioExecutor =
new ThreadPoolExecutor(5, 10, 2000,
TimeUnit.SECONDS, ioQueue);
private static ArrayBlockingQueue processQueue = new ArrayBlockingQueue(50);
private static ThreadPoolExecutor processExecutor = new
ThreadPoolExecutor(5, 10, 2000,
TimeUnit.SECONDS, processQueue);
SocketSessionImpl( Selector sel, SocketChannel ch,
ServiceHandler defaultHandler) throws IOException
{
this.ch = ch;
this.handler = defaultHandler;
this.remoteAddress = ch.socket().getRemoteSocketAddress();
this.localAddress = ch.socket().getLocalSocketAddress();
this.creationTime = System.currentTimeMillis();
this.output.clear();
ch.configureBlocking(false);
sk = ch.register(sel, 0);
sk.attach(this);
sk.interestOps(SelectionKey.OP_READ);
sel.wakeup();
}
public void run() {
try {
if (state == SESSIONSTATE.READING) read();
else if (state == SESSIONSTATE.SENDING) send();
}
catch (IOException ioe) {
logger.error("run():", ioe);
}
finally {
...
}
}
public synchronized void read() throws IOException
{
try
{
input.clear();
int readBytes = 0;
int ret;
try
{
while( ( ret = ch.read( input ) ) > 0 )
{
readBytes += ret;
}
}
finally
{
input.flip();
}
BaseServiceRequest req = new BaseServiceRequest(input);
BaseServiceResponse res = new BaseServiceResponse(output);
processExecutor.execute(new Processor(req,res));
}
catch( Throwable e )
{
logger.error("read():", e);
}
finally
{
input.clear();
}
}
public synchronized void send() throws IOException
{
int count = ch.write( output );
bytesWritten = bytesWritten + count;
if( !output.hasRemaining() )
{
logger.debug("Written " + bytesWritten + " bytes. Changing state to READING.");
state = SESSIONSTATE.READING;
sk.interestOps(SelectionKey.OP_READ);
bytesWritten = 0;
output.clear();
}
}
}
Processor
// Inner Class of SocketIoSessionImpl
class Processor implements Runnable {
private ServiceRequest req;
private ServiceResponse res;
public Processor(ServiceRequest req, ServiceResponse res) {
this.req = req;
this.res = res;
}
public void run() {
try {
handler.process(req, res);
state = SESSIONSTATE.SENDING;
sk.interestOps(SelectionKey.OP_WRITE);
sk.selector().wakeup();
ioExecutor.execute(new Sender());
}
catch (Throwable t) {
logger.error("Error Processing request, Reason:", t);
}
}
}
Sender
// Inner Class of SocketIoSessionImpl
class Sender implements Runnable {
public void run() {
try {
send();
}
catch (Throwable t) {
logger.error("Error sending response, Reason:", t);
}
}
A service implementation using this framework has to implement the ServiceHandler interface which the Processor calls to invoke the service. An echo service could be implemented as:
public class EchoServiceHandler implements
ServiceHandler {
public void process(ServiceRequest req, ServiceResponse res) {
ByteBuffer rb = ( ByteBuffer ) req.getReadBuffer();
// Write the received data back to remote peer
ByteBuffer wb = res.getSendBuffer();
wb.put( rb );
wb.flip();
res.send();
}
}
Thread Pool Size
How many threads should the thread pools have? It depends on the kinds of tasks the worker threads perform. If the tasks in the work queue are compute-bound, then a thread pool of N or N+1 threads on an N-processor system will generally achieve maximum CPU utilization.
For tasks that may wait for I/O to complete i.e. they are mix of compute and I/O bound then application has to be profiled using profiling tools to get ratio of waiting time to service time for a typical service request. For an N-processor system a good thumb rule is to have N * (1 + waiting time/service time) threads in the pool for optimal performance and CPU utilization.
Monday, October 30, 2006
Real time systems and Java
Writing real-time system is not easy in Java because of following:
- Garbage collection - the gc can kick in anytime and there is no upper bound on how long gc will run to reclaim memory. A full gc with compaction (due to heavy fragmentation) can cause stop-the-world pause at worst possible time for a time-sensitive code block.
- Just-in-time compilation - the JIT or hotspot compilation can happen at a time when time critical code is executing leading to unacceptable delay.
- Class initialization - occurs at first use, may result in initialization of other classes, leading to performance issues at time critical code execution.
- Collection and array causing memory and cpu related issues - such as large array being allocated and copied due to array resizing (of ArrayList, Vector, StringBuffer). Or internal rehashing of hash maps, hash sets using precious cpu time when it is needed the most.
- Use of time-deterministic library such as Javolution.
- Initialize all required classes at applicaton startup. Strategies such as object pooling with weak object references can be used.
- Minimize the need for GC to execute: not allocating large objects (recycling objects is much preferred) so as to avoid GC compaction due to fragmentation, creating large number of short-lived objects.
Sunday, October 29, 2006
Staged Event-Driven Architecture (SEDA)
Staged Event-Driven Architecture or SEDA is very a interesting concept for building high performance software systems. Its is a classical "pipes & filter" software architecture (see Garlan & Shaw paper Introduction to Software Architecture) with admission control policies attached to each pipe (called queue in SEDA) to manage load bursts without global degradation of performance. The best way to describe SEDA is to quote the originator of the SEDA (Matt Welsh) from his web site:
It would be an interesting exercise to marry ACE (The ADAPTIVE Communication Environment) concepts of Reactor, Acceptor, Handler pattern with SEDA where Reactor to Acceptor handoff is performed by queueing request and similarly from Acceptor to Handler handoff is performed via another queue. We could write thread pools and configure fixed number of threads to process Accetor and Handler messages to achieve high throughput.
SEDA is an acronym for staged event-driven architecture, and decomposes a complex, event-driven application into a set of stages connected by queues. This design avoids the high overhead associated with thread-based concurrency models, and decouples event and thread scheduling from application logic. By performing admission control on each event queue, the service can be well-conditioned to load, preventing resources from being overcommitted when demand exceeds service capacity. SEDA employs dynamic control to automatically tune runtime parameters (such as the scheduling parameters of each stage), as well as to manage load, for example, by performing adaptive load shedding. Decomposing services into a set of stages also enables modularity and code reuse, as well as the development of debugging tools for complex event-driven applications.
It would be an interesting exercise to marry ACE (The ADAPTIVE Communication Environment) concepts of Reactor, Acceptor, Handler pattern with SEDA where Reactor to Acceptor handoff is performed by queueing request and similarly from Acceptor to Handler handoff is performed via another queue. We could write thread pools and configure fixed number of threads to process Accetor and Handler messages to achieve high throughput.
Sunday, May 14, 2006
Lookup or Reference Data, Hibernate and Second Level Caching
Using hibernate's second level caching with read-only caching for a class leads to following error:
The mapping for corresponding class is as follows:
The reason for the error is that hibernate tries to flush the session after the get and implictly issues save/update even thoough nothing has changed.
This error can be resolved by setting mutable="false" for the class mapping in hibernate mapping for the cacheable object. This tells hibernate that no update is required for an existing object (record). Modifying the above mapping to following will fix the problem:
Second cache configuration setting have not been shown in above snippets.
Exception in thread "main" java.lang.UnsupportedOperationException: Can't write to a readonly object
at org.hibernate.cache.ReadOnlyCache.lock(ReadOnlyCache.java:43)
at org.hibernate.action.EntityUpdateAction.execute(EntityUpdateAction.java:77)
at org.hibernate.engine.ActionQueue.execute(ActionQueue.java:243)
at org.hibernate.engine.ActionQueue.executeActions(ActionQueue.java:227)
at org.hibernate.engine.ActionQueue.executeActions(ActionQueue.java:141)
at org.hibernate.event.def.AbstractFlushingEventListener.performExecutions(AbstractFlushingEventListener.java:296)
at org.hibernate.event.def.DefaultFlushEventListener.onFlush(DefaultFlushEventListener.java:27)
at org.hibernate.impl.SessionImpl.flush(SessionImpl.java:980)
at org.springframework.orm.hibernate3.HibernateAccessor.flushIfNecessary(HibernateAccessor.java:394)
at org.springframework.orm.hibernate3.HibernateTemplate.execute(HibernateTemplate.java:366)
at org.springframework.orm.hibernate3.HibernateTemplate.get(HibernateTemplate.java:445)
at org.springframework.orm.hibernate3.HibernateTemplate.get(HibernateTemplate.java:439)
at com.isd.common.persistence.dao.BaseDaoHibernate.get(BaseDaoHibernate.java:33)
at com.isd.common.service.lookupcache.LookupCacheManagerImpl.getLookupType(LookupCacheManagerImpl.java:61)
at com.isd.common.service.lookupcache.TestLookupCache.main(TestLookupCache.java:36)
The mapping for corresponding class is as follows:
<!-- Lookup tables -->
<class name="com.isd.common.service.lookupcache.LookupType" table="LookupType" dynamic-update="false">
<cache usage="read-only"/>
...
...
The reason for the error is that hibernate tries to flush the session after the get and implictly issues save/update even thoough nothing has changed.
This error can be resolved by setting mutable="false" for the class mapping in hibernate mapping for the cacheable object. This tells hibernate that no update is required for an existing object (record). Modifying the above mapping to following will fix the problem:
<!-- Lookup tables -->
<class name="com.isd.common.service.lookupcache.LookupType" table="LookupType" mutable="false" dynamic-update="false">
<cache usage="read-only"/>
Second cache configuration setting have not been shown in above snippets.
Sunday, October 30, 2005
OOPSLA 2005
Attended OOPSLA 2005 from October 16-20 in San Diego. Since coming back my broadband network access has been down. Finally my connection is back. OOPSLA is always a very exciting and rejuvenating experience for me. I always come back all charged up. This year was no different. And being OOPSLA's 20th year, it added more to the gathering and some of the sessions and talks.
For me the BoF session with Grady Booch on Wednesday (October 19) was the best moment. Grady's next project is a very ambitious effort - a handbook of software architecture. Check his web site. If you register you can see the work in progress and realize the grandness of his effort.
I also enjoyed talk by David P. Reed on TeaTime - A Scalable Real-Time Multi-User Architecture.
For me the BoF session with Grady Booch on Wednesday (October 19) was the best moment. Grady's next project is a very ambitious effort - a handbook of software architecture. Check his web site. If you register you can see the work in progress and realize the grandness of his effort.
I also enjoyed talk by David P. Reed on TeaTime - A Scalable Real-Time Multi-User Architecture.
Monday, September 19, 2005
Availability, External System Connectivity, and SOA
Web Services and SOA are getting a lot of press but the technology and platform for truly making highly available system by composing services available from other enterprise systems exposed as a web service is still in its infancy, specs are still being developed by various standards bodies (by OASIS such as WS-Relibility and other standards bodies). In the meanwhile we need to build failover and reliability in the architectural framework of the application. Some of the fundamental principles of architetcural framework that provides external system access using web services are:
- Create a bounded pool of connections to the remote system: This is important - it prevents all application server threads from being used up while waiting for a response in case backend is non-responsive or crashes half way while processing a request. We have seen scenarios where application server stops responding completely because all threads get stuck waiting for response from one or two critical backend service.
- Periodically close connections that have been open for a while for better load balancing i.e. age connections. This is very useful for hardware based load balancers which load balance at the time of HTTP connecton setup.
- Enable and set appropriate network level connection and read timeouts to prevent stuck applications: This is extremely important because of HTTP's request/response semantics. We have seen many a transactions getting stuck forever when the backend/external service becomes unavailable and the system does not get TCP reset (connection termination) message. This leads to TCP half open connection and the sender waits for a response forever unless read timeouts are implemented.
- Close and discard connections from the connection pool after error.
Java Net, DNS Caching and Availability
Many organizations are deploying global load balancers to load balance across geographically distributed data centers. This also imporves service availability since one data center can be taken offline for maintainance without disruption to service. The GLSBs use DNS resolution to direct traffic to server farms. To ensure that the system that uses other backend web services is highly available, can handle failovers, and recover from failover without requiring a server re-start do the following:
The DNS name to IP address resolution capability is provided by InetAddress class (part of java.net package - core networking package for Java Platform). The default implementation is to cache DNS-to-IP resolution FOREVER. In fact InetAddress will also cache un-successful DNS-to-IP resolution for 10 seconds (default).
Java 1.4 and above versions provide system properties to modify DNS caching behavior by setting the the cache TTL (time-to-live) and negative cache TTL (i.e. failed resolution) documented here, http://java.sun.com/j2se/1.4.2/docs/guide/net/properties.html.
Unfortunately there is no standard or formally documented way of changing DNS caching behavior in versions Java 1.3 and below. However there is a non-standard Sun proprietary system property that can be set at Java command line to change the behavior (Java 1.4 documentation actually includes this property name). The property is
sun.net.inetaddr.ttl
The system property is specified at command line as:
java -Dsun.net.inetaddr.ttl=0
Values are interpreted as:
-1 (default) => Cache FOREVER
0 => Disable caching. This means every call to resolve address will require DNS query.
+integer => In seconds TTL for cache entry i.e. time after which cache entry is stale. After this time, a call for DNS-to-IP will result in DNS query.
- Use URL to connect to service endpoint, so that DNS lookup is used to determine service endpoint IP address.
- Java DNS cache TTL is set to a reasonable value. By DEFAULT Java's DNS resolution will cache DNS to IP resolution FOREVER. After the initial DNS-to-IP (successful) resolution only way to force Java to make DNS query is to re-cycle the JVM. Obviously this is not very good for building highly available system.
The DNS name to IP address resolution capability is provided by InetAddress class (part of java.net package - core networking package for Java Platform). The default implementation is to cache DNS-to-IP resolution FOREVER. In fact InetAddress will also cache un-successful DNS-to-IP resolution for 10 seconds (default).
Java 1.4 and above versions provide system properties to modify DNS caching behavior by setting the the cache TTL (time-to-live) and negative cache TTL (i.e. failed resolution) documented here, http://java.sun.com/j2se/1.4.2/docs/guide/net/properties.html.
Unfortunately there is no standard or formally documented way of changing DNS caching behavior in versions Java 1.3 and below. However there is a non-standard Sun proprietary system property that can be set at Java command line to change the behavior (Java 1.4 documentation actually includes this property name). The property is
sun.net.inetaddr.ttl
The system property is specified at command line as:
java -Dsun.net.inetaddr.ttl=0
Values are interpreted as:
-1 (default) => Cache FOREVER
0 => Disable caching. This means every call to resolve address will require DNS query.
+integer => In seconds TTL for cache entry i.e. time after which cache entry is stale. After this time, a call for DNS-to-IP will result in DNS query.
Monday, August 01, 2005
Light Weight Containers - Inversion Of Control (IoC) or Dependency Injection (DI) Frameworks
Last few years have seen a huge interest in lightweight frameworks in enterprise Java world to counter the complexity of heavyweight containers such as EJB. I have been reading a lot of people rave about IoC and how it makes life of a developer easier. While reading EJB3 first public draft spec, I saw references to dependency injection, this thing has arrived and I had no clue as to what it is. So I decided to get a feel for IoC. These are my findings so far.
IoC Defined
Objects in a system are associated with each other and they collaborate to provide a piece of business functionality. The objects depend on each other. Traditionally the task of resolving object dependency and setting up object collaborators is required programmatically before executing the business logic. A lot of code is required to wire up all the dependent objects. In J2EE world this often translates to performing JNDI lookup via a service locator to find the objects and instantiating them and setting up appropriate attribute in the business object. IoC frameworks invert the control with respect to resolution, creation and setting up of collaborators when performing a task or piece of business functionality or use case. For example in a customer relationship management system, the act of creating a customer may involve creating the customer object itself, creating customer contacts and creating products the customer has purchased. A customer service implemented as a session façade will need collaborator objects: Customer Business Object (Customer BO), Contact BO and Product BO. These business objects can be POJOs or EJBs (stateless that use DAO or entity EJBs for persistence). In a non IoC environment the customer service façade will need to find/locate the collaborators (Customer BO, Contact BO and Product BO), create them and setup the appropriate attributes before implementing business function. In an IoC environment, on the other hand , one simply declares the dependency (using a mechanism provided by the IoC framework) on the collaborators of customer service façade. At runtime the IoC framework ensures that these collaborators are wired up (again via an IoC framework specific mechanism) and ready to use before a customer business operation is called on it (say create). Its obvious from the description that instead of customer service façade controlling the collaborators, something else is controlling it - the IoC framework - hence the name Inversion of Control.
Any IoC framework has following characteristics (from Mike Spille's Blog):
Types of DI
There are 3 types of IoC frameworks. These are known, rather unimaginatively, as type 1, type 2 and type 3 based on how collaborators are setup i.e. dependency is injected. Martin Fowler gave them a more meaningful name:
Essential Tensions
Constructor Vs Setter
Constructor-based injection wires up the dependencies at object construction time. This gives a valid object at creation. However if there are many dependencies, the constructor arguments can become large and cumbersome. The setter based construction is simpler, more intuitive and provides flexibility that might not be available with constructors.
Configuration file vs Java Code wiring
Configuration file gives more flexibility and the advantages are obvious. The dependencies can be modified just by modifying the config files without requiring a compile or build. The Java code wiring is useful in situations where component assembly is complex and requires logic (if then else) – in those scenarios expressing dependencies using config files becomes difficult. Only logical choice is a programming language with rich sematics for complex logic. Java code wiring is going to be simpler and easier. A dynamic language like Groovy can be really useful here since being dynamic it won’t require compilation whereas Java would.
Advantages
Popular DI/IoC Frameworks
IoC Defined
Objects in a system are associated with each other and they collaborate to provide a piece of business functionality. The objects depend on each other. Traditionally the task of resolving object dependency and setting up object collaborators is required programmatically before executing the business logic. A lot of code is required to wire up all the dependent objects. In J2EE world this often translates to performing JNDI lookup via a service locator to find the objects and instantiating them and setting up appropriate attribute in the business object. IoC frameworks invert the control with respect to resolution, creation and setting up of collaborators when performing a task or piece of business functionality or use case. For example in a customer relationship management system, the act of creating a customer may involve creating the customer object itself, creating customer contacts and creating products the customer has purchased. A customer service implemented as a session façade will need collaborator objects: Customer Business Object (Customer BO), Contact BO and Product BO. These business objects can be POJOs or EJBs (stateless that use DAO or entity EJBs for persistence). In a non IoC environment the customer service façade will need to find/locate the collaborators (Customer BO, Contact BO and Product BO), create them and setup the appropriate attributes before implementing business function. In an IoC environment, on the other hand , one simply declares the dependency (using a mechanism provided by the IoC framework) on the collaborators of customer service façade. At runtime the IoC framework ensures that these collaborators are wired up (again via an IoC framework specific mechanism) and ready to use before a customer business operation is called on it (say create). Its obvious from the description that instead of customer service façade controlling the collaborators, something else is controlling it - the IoC framework - hence the name Inversion of Control.
Any IoC framework has following characteristics (from Mike Spille's Blog):
- IoC framework controls the creation of objects.
- IoC framework manages the lifecycle of the objects.
- IoC framework resolves the dependencies between objects it manages.
Types of DI
There are 3 types of IoC frameworks. These are known, rather unimaginatively, as type 1, type 2 and type 3 based on how collaborators are setup i.e. dependency is injected. Martin Fowler gave them a more meaningful name:
- Constructor Based Injection (or Type 1): In this the constructor of the object declares as argument its collaborator (or dependencies). The IoC frameworks via introspection will determine the dependencies and inject them when constructing the object.
- Setter Based Injection (or Type 2): In this the dependency on collaborators is declared using setter methods (a la JavaBean style).
- Interface Based Injection (or Type 3): In this type the dependency is defined using interfaces.
Essential Tensions
Constructor Vs Setter
Constructor-based injection wires up the dependencies at object construction time. This gives a valid object at creation. However if there are many dependencies, the constructor arguments can become large and cumbersome. The setter based construction is simpler, more intuitive and provides flexibility that might not be available with constructors.
Configuration file vs Java Code wiring
Configuration file gives more flexibility and the advantages are obvious. The dependencies can be modified just by modifying the config files without requiring a compile or build. The Java code wiring is useful in situations where component assembly is complex and requires logic (if then else) – in those scenarios expressing dependencies using config files becomes difficult. Only logical choice is a programming language with rich sematics for complex logic. Java code wiring is going to be simpler and easier. A dynamic language like Groovy can be really useful here since being dynamic it won’t require compilation whereas Java would.
Advantages
- Removes code clutter, leading to more readable code.
- Provides a great deal of convenience - one can focus on implementing the business use case at hand rather than worrying about all the plumbing that sets up all the collaborators.
- Provides a great deal of flexibility - if one needs to have a different version of collaborator (i.e. different implementation), simply modify the dependency in configuration file and that's it. No code anywhere need to be modified. IoC greatly facilitates building loosely coupled systems.
- Simplifies unit testing - one of the greatest pain points with the heavyweight containers such as J2EE (EJB in particular) is that unit testing is very difficult. With IoC framework, one can very easily write up a mock object that implements the collaborator interfaces and configure this mock object. This flexibility is one of the key reasons for the current popularity of light-weight containers.
Popular DI/IoC Frameworks
Saturday, July 30, 2005
IoC Containers Have Arrived
IoC containers have arrived big time and now are very much in mainstream software development - EJB3 has IoC features (no more JNDI lookup of resources and EJBs are required - these can be injected by container using Java 5 annotations - although JNDI lookup is supported). Time to read on IoC containers and in particular Spring. Geronimo guys are planning to use Spring for assembling Geronimo components - interesting. J2EE server uses Spring and Spring uses J2EE container services - that shows power of IoC and its applicability in developing flexible and loosely coupled systems.
Open Source Single Sign On Solutions
Some nice open source single sign-on solutions:
Not really a single-sign on solution but security solution designed for Spring:
Acegi Security project from Spring framework.
Not really a single-sign on solution but security solution designed for Spring:
Acegi Security project from Spring framework.
Tuesday, July 19, 2005
Double-Checked Locking is Broken in Java
The double-checked locking is broken in Java and it doesn't work. This declaration explains in great detail why?
Double-Checked Locking is Broken
This widely used idiom in singletons doesn't work:
An approach that will work is to do the following:
Double-Checked Locking is Broken
This widely used idiom in singletons doesn't work:
public class ClassA {
private static ClassA INSTANCE;
private ClassA() {
super();
init();
}
public static ClassA getInstance() {
if (null == INSTANCE)
synchronized (this) {
if (null == INSTANCE) {
INSTANCE = new ClassA();
}
}
return INSTANCE;
}
}
An approach that will work is to do the following:
public class ClassA {
private static final ClassA INSTANCE = new ClassA();
private ClassA() {
super();
init();
}
public static ClassA getInstance() {
return INSTANCE;
}
}
Sunday, July 17, 2005
Don't use java.rmi.server.UID for generating Unique IDs
There is a well known bug in java.rmi.server.UID in all the JDKs prior to Java 5. The problem occurs when two or more JVMs are running on the same host and are started exactly in the same millisecond. We found the bug the hard way while troubleshooting a real production problem that was rather painful.
UID as generated by java.rmi.server.UID is comprised of a host unique JVMID, followed by current time in milliseconds and followed by a sequence number as shown below:
JVMID – Time in milliseconds since Jan 1, 1970 – Seq No
An example UID is:
29b7fbc2 - 0000-0104-0bb5-afc9 - b2e0
where
29b7fbc2 - JVM Identifier unique to the machine.
0000-0104-0bb5-afc9 - Milliseconds since the epoch of 1970. In this example the value is May 23, 2005 18:39:13 EDT. This will change only when the sequence number rolls over. The JVM does not get the current time for every UID request in order to improve performance. Therefore, the msec time here is the time when the sequence number rolls over NOT the time when the UID was created.
b2e0 - Sequence number which counts from 8000 to 0 to 7FFF (in HEX).
UID is widely used as a starting point for generating unique Ids. We too used the UID: our UID scheme simply appended 3rd and 4th byte of host IP address to the number generated by java.rmi.server.UID. This UID was used as session identifier for web transactions with one of our legacy backend system. This scheme worked fine over a year and half without problem. Suddenly, about 2 months back, we started seeing duplicate sessions ids. Sometimes (we couldn’t nail how) one user would steal the transaction from another user and our backend system would actually commit the transaction incorrectly for the wrong user. We were puzzled and baffled. We looked at system clock for the UNIX server, thinking that the system clock was not ticking and time was not advancing (ruled out later, it started becoming random with respect to UNIX server). May be the time synchronization process for the cluster was setting the system clock back for these servers. After much analysis that was determined not be the case. We looked for similar problems but for the most part we were at a loss.
To give a brief idea of our system: it is a J2EE based very high volume web site. This system is consumer facing, 24 by 7, global e-commerce site and is a major revenue generating channel for the company. It interfaces with Mainframe based legacy systems for core business transactions. Another important aspect, to meet performance requirements, we had to stand up 2 JVMs per host about 8 months back.
Needless to say the heat was on, this problem although very miniscule (only 7 or 8 cases was reported among upwards of five hundred thousand transactions) nonetheless, it had everybody worried and more so since we were clueless. Company’s name and trust was at stake if this continued for long. The customers who’s transactions were messed up, called in our customer care line and got the problem resolved.
We got a lucky break a few weeks back when we were troubleshooting one such occurrence. It came to our attention that this problem started after a cluster switch was performed and ripple start of 2nd set of JVMs was executed. Then somebody mentioned that last time also the problem started after a server restart. That got us thinking – something to do with JVM restarts – at least some semblance of repeatable pattern. We had always fixed the problem by shutting down the offending application servers and re-starting them. What if there is a bug in UID generation? We knew for sure that the last 2 bytes of the UID will be same for all UIDs on a given host. How is JVM id determined? Does it use start up time (we had actually ruled this out earlier assuming Java will have a smarter way of guaranteeing JVM uniqueness on a host and must not be based on JVM startup time. Bad assumption)? We googled “bug in java.rmi.server.UID” and there it was !! (we love google, the best customer support and knowledge base in the world). We quickly copied the programs posted with the bug in the Sun’s Java bug database to reproduce the problem and sure enough we did it very reliably. So under some circumstances our ripple start scripts were starting the two application servers (or JVMs) on a given host in the cluster exactly at the same millisecond and when it happened (which was very random to us since we have 11 servers with 26 JVMs in our primary cluster) the two JVMs would start generating duplicate UIDs.
Moral of the story, don’t rule out bugs in core Java libraries and don’t assume that Sun is always very smart and will always have elegant solutions. And please use google or search Sun's Java bug database for finding Java bugs first. It might just save many a heart burns and sleepless nights. We were dumbfounded to learn that this bug has been in Java since its inception and the bug was first filed in 1999. Second all of us were looking rather chastised and humbled, how come we didn’t know? Most of us have been working with Java since 1998.
Note: Please see the bug description for details of the bug and the circumstances under which it can occur. Our fix was that we wrote our own UID generator. Java 5 fixes the problem by using new SecureRandom().nextInt() (see source code in src.zip in $JAVA_HOME distributed with JDK 5, src/java/rmi/server/UID.java) for JVM unique id instead of new Object().hashCode() (see source code in src.zip in $JAVA_HOME distributed with JDK 1.4, 1.3, 1.2 etc., src/java/rmi/server/UID.java) in pre Java 5 versions.
UID as generated by java.rmi.server.UID is comprised of a host unique JVMID, followed by current time in milliseconds and followed by a sequence number as shown below:
JVMID – Time in milliseconds since Jan 1, 1970 – Seq No
An example UID is:
29b7fbc2 - 0000-0104-0bb5-afc9 - b2e0
where
29b7fbc2 - JVM Identifier unique to the machine.
0000-0104-0bb5-afc9 - Milliseconds since the epoch of 1970. In this example the value is May 23, 2005 18:39:13 EDT. This will change only when the sequence number rolls over. The JVM does not get the current time for every UID request in order to improve performance. Therefore, the msec time here is the time when the sequence number rolls over NOT the time when the UID was created.
b2e0 - Sequence number which counts from 8000 to 0 to 7FFF (in HEX).
UID is widely used as a starting point for generating unique Ids. We too used the UID: our UID scheme simply appended 3rd and 4th byte of host IP address to the number generated by java.rmi.server.UID. This UID was used as session identifier for web transactions with one of our legacy backend system. This scheme worked fine over a year and half without problem. Suddenly, about 2 months back, we started seeing duplicate sessions ids. Sometimes (we couldn’t nail how) one user would steal the transaction from another user and our backend system would actually commit the transaction incorrectly for the wrong user. We were puzzled and baffled. We looked at system clock for the UNIX server, thinking that the system clock was not ticking and time was not advancing (ruled out later, it started becoming random with respect to UNIX server). May be the time synchronization process for the cluster was setting the system clock back for these servers. After much analysis that was determined not be the case. We looked for similar problems but for the most part we were at a loss.
To give a brief idea of our system: it is a J2EE based very high volume web site. This system is consumer facing, 24 by 7, global e-commerce site and is a major revenue generating channel for the company. It interfaces with Mainframe based legacy systems for core business transactions. Another important aspect, to meet performance requirements, we had to stand up 2 JVMs per host about 8 months back.
Needless to say the heat was on, this problem although very miniscule (only 7 or 8 cases was reported among upwards of five hundred thousand transactions) nonetheless, it had everybody worried and more so since we were clueless. Company’s name and trust was at stake if this continued for long. The customers who’s transactions were messed up, called in our customer care line and got the problem resolved.
We got a lucky break a few weeks back when we were troubleshooting one such occurrence. It came to our attention that this problem started after a cluster switch was performed and ripple start of 2nd set of JVMs was executed. Then somebody mentioned that last time also the problem started after a server restart. That got us thinking – something to do with JVM restarts – at least some semblance of repeatable pattern. We had always fixed the problem by shutting down the offending application servers and re-starting them. What if there is a bug in UID generation? We knew for sure that the last 2 bytes of the UID will be same for all UIDs on a given host. How is JVM id determined? Does it use start up time (we had actually ruled this out earlier assuming Java will have a smarter way of guaranteeing JVM uniqueness on a host and must not be based on JVM startup time. Bad assumption)? We googled “bug in java.rmi.server.UID” and there it was !! (we love google, the best customer support and knowledge base in the world). We quickly copied the programs posted with the bug in the Sun’s Java bug database to reproduce the problem and sure enough we did it very reliably. So under some circumstances our ripple start scripts were starting the two application servers (or JVMs) on a given host in the cluster exactly at the same millisecond and when it happened (which was very random to us since we have 11 servers with 26 JVMs in our primary cluster) the two JVMs would start generating duplicate UIDs.
Moral of the story, don’t rule out bugs in core Java libraries and don’t assume that Sun is always very smart and will always have elegant solutions. And please use google or search Sun's Java bug database for finding Java bugs first. It might just save many a heart burns and sleepless nights. We were dumbfounded to learn that this bug has been in Java since its inception and the bug was first filed in 1999. Second all of us were looking rather chastised and humbled, how come we didn’t know? Most of us have been working with Java since 1998.
Note: Please see the bug description for details of the bug and the circumstances under which it can occur. Our fix was that we wrote our own UID generator. Java 5 fixes the problem by using new SecureRandom().nextInt() (see source code in src.zip in $JAVA_HOME distributed with JDK 5, src/java/rmi/server/UID.java) for JVM unique id instead of new Object().hashCode() (see source code in src.zip in $JAVA_HOME distributed with JDK 1.4, 1.3, 1.2 etc., src/java/rmi/server/UID.java) in pre Java 5 versions.
Saturday, July 16, 2005
Commons Logging - To Use or Not To Use
Now that we have looked at Java ClassLoading in detail, its time to take a look at Apache Jakarta Commons Logging and answer the question: whether to use or not to use Commons Logging in J2EE environment? Commons Logging provides a nice abstract logging API, insulating application code from being tied to a specific logging implementation. Use of Commons Logging provides portability across logging implementations such as log4j or jdk logging. On the face of it this looks like a neat idea. I can change the logging implementation without changing a line of code. However that was not the intent of Commons Logging (See Rod Waldoff’s blog) and there are well known problems using Commons Logging in J2EE environment due to ClassLoader problems and auto-discovery of a logging implementation and logging configuration. Ceku Gulcu, creator of log4j, has a detailed technical discussion on classloader problem. Ceku Gulcu takes a detailed look at problems using Commons Logging in this article “Think again before adopting the commons-logging API”. From this article:
A downside of using Commons Logging is that it takes away some of the advance features of an underlying logging implementation (being an abstraction across various logging implementation, it can only support features common across logging frameworks) such as Nested Diagnostic Context (NDC) or Mapped Diagnostic Context (MDC) capability of log4j. Another issue with it is that it makes logging component a tad complex. And it can introduce problems which can be difficult to debug. One can waste hours debugging classloader issues or why your application is not reading your logging configuration. All this complexity is unwarranted. Even creator of Commons Logging Rod Waldhoff has acknowledged “Commons Logging was my fault”.
Inspite of these problems Commons Logging has its utility. So when and where should it be used? Again from Rod Waldhoff’s blog:
“The commons-logging API supporting multiple logging frameworks has its own "discovery process" which is based on the resources available to a particular classloader. In addition, the commons-logging API will create its own logger wrapper for each and every class loader in use within your application. The class loader based automatic "discovery process" is the principal weakness of the commons-logging API because it results in a substantial jump in complexity.”
A downside of using Commons Logging is that it takes away some of the advance features of an underlying logging implementation (being an abstraction across various logging implementation, it can only support features common across logging frameworks) such as Nested Diagnostic Context (NDC) or Mapped Diagnostic Context (MDC) capability of log4j. Another issue with it is that it makes logging component a tad complex. And it can introduce problems which can be difficult to debug. One can waste hours debugging classloader issues or why your application is not reading your logging configuration. All this complexity is unwarranted. Even creator of Commons Logging Rod Waldhoff has acknowledged “Commons Logging was my fault”.
Inspite of these problems Commons Logging has its utility. So when and where should it be used? Again from Rod Waldhoff’s blog:
“In fact, there are very limited circumstances in which Commons Logging is useful. If you're building a stand-alone application, don't use commons-logging. If you're building an application server, don't use commons-logging. If you're building a moderately large framework, don't use commons-logging. If however, like the Jakarta Commons project, you're building a tiny little component that you intend for other developers to embed in their applications and frameworks, and you believe that logging information might be useful to those clients, and you can't be sure what logging framework they're going to want to use, then commons-logging might be useful to you.”
Saturday, July 09, 2005
WebSphere 5.x Classloaders.
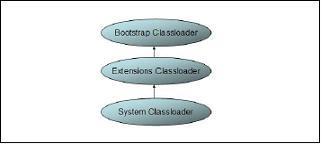 Picture 1 Java Classloader Hierarchy.
Picture 1 Java Classloader Hierarchy.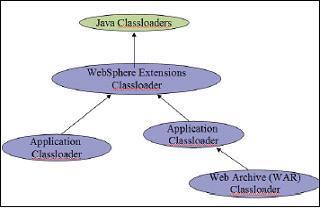 Picture 2 WebSphere Classloader Hierarchy.
Picture 2 WebSphere Classloader Hierarchy.Java Classloaders
The standard Java (JSE) VM has three classloaders: the bootstrap classloader, the extensions classloader, and the system classloader.
Bootstrap Classloader: The bootstrap classloader is responsible for loading the core Java libraries, that is
Extensions classloader: The extensions classloader is responsible for loading the code in the extensions directories (
System Classloader: The system classloader is responsible for loading the code that is found on java.class.path, which ultimately maps to the system CLASSPATH variable. This classloader is implemented by the sun.misc.Launcher$AppClassLoader class.
Picture 1 shows the standard Java classloader hierarchy.
Delegation is a key concept to understand when dealing with classloaders. It states which classloader in the classloader hierarchy loads a class. By default when a Java program needs a class, the context (or current) classloader delegates class loading to its parent before trying to load the class itself. This is the default policy for standard JVM classloaders. For example if the system classloader needs to load a class, it first delegates to the extensions classloader, which in turn delegates to the bootstrap classloader. If the parent classloader cannot load the class, the child classloader tries to find the class in its own repository. In this manner, a classloader is only responsible for loading classes that its ancestors cannot load. A classloader can only find classes up in the hierarchy, not down. This is a very important concept because at runtime if a class tries to load a class not visible to the classloader that loaded it or any of it parents then NoClassDefFoundError will be thrown.
WebSphere Application Server 5.x classloader hierarchy is shown in picture 2 above.
In general each enterprise application (EAR) gets its own classloader and each web application (WAR) within an EAR or without an EAR i.e. standalone WAR gets its own classloader. All EJB JAR files within an application are always loaded by the same classloader. The application classloader policy and WAR classloader policy control the actual runtime classloader hierarchy.
WebSphere Extensions Classloader
The WebSphere extensions classloader, whose parent is the Java system classloader, is primarily responsible for the loading of the WebSphere class libraries in the following directories:
-
-
-
-
The WebSphere runtime is loaded by the WebSphere extensions classloader based on the ws.ext.dirs system property, which is initially derived from the WS_EXT_DIRS environment variable set in the setupCmdLine script file found in $WAS_HOME/bin directory. The default value of ws.ext.dirs is the following:
SET WAS_EXT_DIRS=%JAVA_HOME%/lib;%WAS_HOME%/classes;%WAS_HOME%/lib;
%WAS_HOME%/lib/ext;%WAS_HOME%/web/help;
%ITP_LOC%/plugins/com.ibm.etools.ejbdeploy/runtime
The RCP directory is intended to be used for fixes and other APARs (IBM terminology for patches) that are applied to the application server runtime. These patches override any copies of the same files lower in the RP and RE directories. The RP directory contains the core application server runtime files. The bootstrap classloader first finds classes in the RCP directory then in the RP directory. The RE directory is used for extensions to the core application server runtime. Each directory listed in the ws.ext.dirs environment variable is added to the WebSphere extensions classloaders classpath. In addition, every JAR file and/or ZIP file in the directory is added to the classpath. You can extend the list of directories/files loaded by the WebSphere extensions classloaders by setting a ws.ext.dirs custom property to the Java virtual machine settings of an application server.
Application Extensions Classloader
In WebSphere Application Server Version 4.0, one could drop JAR files under
Shared Libraries
It is recommended that shared libraries be used to point to a set of JARs (for example, a framework), and associate those JARs to an application or application server.
Shared libraries consist of a symbolic name, a Java classpath, and a native path (for loading JNI libraries), and can be defined at the cell, node, or server level. However, defining a library at one of the three levels does not cause the library to be loaded. The library must associated to an application and/or application server in order for the classes represented by the shared library to be loaded.
If shared library is associated to an application (EAR), the JARs listed on the shared library path are loaded by the application classloader (together with EJB JARs, RARs and dependency JARs). If the the shared library is associated at the application server level, the JARs listed on the shared library path are loaded by a specific classloader (which you have to define).
Classloading and Delegation mode
There are two possible values for a classloader loading mode: PARENT_FIRST and PARENT_LAST. The default value for classloading mode is PARENT_FIRST. This policy causes the classloader to first delegate the loading of classes to its parent classloader before attempting to load the class from its local classpath. This is the default policy for standard JVM classloaders. If the classloading policy is set to PARENT_LAST, the classloader attempts to load classes from its local classpath before delegating the classloading to its parent. This policy allows an application classloader to override and provide its own version of a class that exists in the parent classloader. Delegation mode can be set for the following classloaders: application classloader, WAR classloader, and shared library classloader.
Classloader Policies
For each application server in the system, the application classloader policy can be set to Single or Multiple.
Single: When the application classloading policy is set to Single, a single application classloader is used to load all EJBs, dependency JARs, and shared libraries within the application server (JVM). If the WAR classloader loading policy has been set to Application, the Web module contents for this particular application are also loaded by this single classloader.
Multiple: When the application classloading policy is set to Multiple, each application will receive its own classloader for loading EJBs, dependency JARs, and shared libraries. Depending on whether the WAR classloader loading policy is set to Module or Application, the Web module may or may not receive its own classloader.
For web application, the WAR classloader policy can be set to Module or Application.
Module: When the WAR classloading policy is set to Module, the Web module gets its own WAR classloader and it loads classes for the Web module.
Application: When the WAR classloading policy is set to Application, the Web module does not get its own WAR classloader. The Web module classes are loaded by application classloader (either single or multiple guided by application classloading policy).
Reloadable Classloaders
The application (EAR classloader) and the Web module classloaders (WAR classloader) are reloadable classloaders. They monitor changes in the application code to automatically reload modified classes. This behavior can be altered at deployment time.
Saturday, April 23, 2005
J2EE, 2PC and XA
Excellent blog on transaction management in J2EE world - a wonderful article on 2PC, XA and the implemention of transaction log - key to transaction management.
Mike Spille Blog on XA.
Mike Spille Blog on XA.
Saturday, April 09, 2005
Default Isolation Levels for Various Databases
SQL SERVER - READ COMMITTED
Sybase - READ COMMITTED
Oracle - READ COMMITTED (supports only READ COMMITTED, SERIALIZABLE and the non-standard READ ONLY)
DB2 - REPEATABLE READ (supports REPEATABLE READ, UNCOMMITTED READ and 2 non-standard levels)
PostgreSQL - REPEATABLE READ (only supports REPEATABLE READ and SERIALIZABLE)
Mysql InnoDB - REPEATABLE READ
Sybase - READ COMMITTED
Oracle - READ COMMITTED (supports only READ COMMITTED, SERIALIZABLE and the non-standard READ ONLY)
DB2 - REPEATABLE READ (supports REPEATABLE READ, UNCOMMITTED READ and 2 non-standard levels)
PostgreSQL - REPEATABLE READ (only supports REPEATABLE READ and SERIALIZABLE)
Mysql InnoDB - REPEATABLE READ
Caching in Service Locator Can Be Harmful
J2EE 1.3 introduced the concept of resource references. Resource references are helpful in breaking down coupling between systems but it also introduced an unintended problem when cached via Service Locator pattern. See this article for reasons why? From the article's introduction - "This article shows how implementations of the Service Locator pattern that include a resource cache can cause code to run incorrectly in J2EE 1.3 and later versions. While the Service Locator pattern itself is still useful, this article will show how caching with this pattern is harmful rather than helpful, why it should be eliminated from service locator implementations, and offer some practical alternatives."
Saturday, November 13, 2004
Web Services, Orchestration and Choreography
From initial reading of Web services workflow technologies, I am completely confused regarding the difference between Orchestration and Choreography.
What is the difference between Web services orchestration and choreohraphy? From my various readings this is the best description I could find:
"Existing specifications for Web services describe the indivisible units of interactions. It has become clear that taking the next step in the development of Web services will require the ability to compose and describe the relationships between lower-level services. Although differing terminology is used in the industry, such as orchestration, collaboration, coordination, conversations, etc., the terms all share a common characteristic of describing linkages and usage patterns between Web services. For the purpose of this document, and without prejudice, we use the term choreography as a label to denote this space."
"Choreography" and "orchestration" are in my view synonymous. Other synonymous terms include "workflow" and "business process automation". All of these terms refer to automatic routing of content, context, and control through a series of distributed business processes.
What is the difference between Web services orchestration and choreohraphy? From my various readings this is the best description I could find:
- Choreography - Web services choreography pertains to the public protocol of a Web service, describing the nature and order of messages exchanged between a Web service and its consumers or peers. WSCI (Web Services Choreography Interface), proposed by BEA and Sun as a specification aimed at describing the flow of messages among interacting Web services and is a Choreography specification.
- Orchestration - Web services orchestration, on the other hand, pertains to the private implementation of a Web service, i.e. describing and executing the interactions and flow among Web services to form collaborative processes or (long-running) business transactions. BPEL4WS (Business Process Execution Language for Web Services) proposed by IBM and Microsoft is an Orchestration specification.
All these technologies are used to construct business processes on top Web services enabling technologies such as SOAP, WSDL, UDDI etc. Both Orchestration and Choreohraphy provide collaboration and coordination mechansim between business.
From Web Services Choreography Working Group Charter the following comment best describes the orchestration and choreohraphy:"Existing specifications for Web services describe the indivisible units of interactions. It has become clear that taking the next step in the development of Web services will require the ability to compose and describe the relationships between lower-level services. Although differing terminology is used in the industry, such as orchestration, collaboration, coordination, conversations, etc., the terms all share a common characteristic of describing linkages and usage patterns between Web services. For the purpose of this document, and without prejudice, we use the term choreography as a label to denote this space."
"Choreography" and "orchestration" are in my view synonymous. Other synonymous terms include "workflow" and "business process automation". All of these terms refer to automatic routing of content, context, and control through a series of distributed business processes.
![]()